

{kind=link}
This weblog is collectively written by Amy Chang, Idan Habler, and Vineeth Sai Narajala.
Immediate injections and jailbreaks stay a serious concern for AI safety, and for good motive: fashions stay prone to customers tricking fashions into doing or saying issues like bypassing guardrails or leaking system prompts. However AI deployments don’t simply course of prompts at inference time (which means when you find yourself actively querying the mannequin): they could additionally retrieve, rank, and synthesize exterior information in actual time. Every of these steps is a possible adversarial entry level.
Retrieval-Augmented Era (RAG) is now commonplace infrastructure for enterprise AI, permitting giant language fashions (LLMs) to acquire exterior data through vector similarity search. RAGs can join LLMs to company data repositories and buyer help methods. However that grounding layer, generally known as the vector embedding area, introduces its personal assault floor generally known as adversarial hubness, and most groups aren’t searching for it but.
However Cisco has you lined. We’d prefer to introduce our newest open supply instrument: Adversarial Hubness Detector.
The Safety Hole: “Zero-Click on” Poisoning
In high-dimensional vector areas, sure factors naturally turn out to be “hubs,” which implies that standard nearest neighbors can present up in outcomes for a disproportionate variety of queries. Whereas this occurs naturally, these hubs might be manipulated to power irrelevant or dangerous content material in search outcomes: a goldmine for attackers. Determine 1 beneath demonstrates how adversarial hubness can influence RAG methods.
By engineering a doc embedding, an adversary can create a “gravity effectively” that forces their content material into the highest outcomes for hundreds of semantically unrelated queries. Latest analysis demonstrated {that a} single crafted hub may dominate the highest outcome for over 84% of take a look at queries.
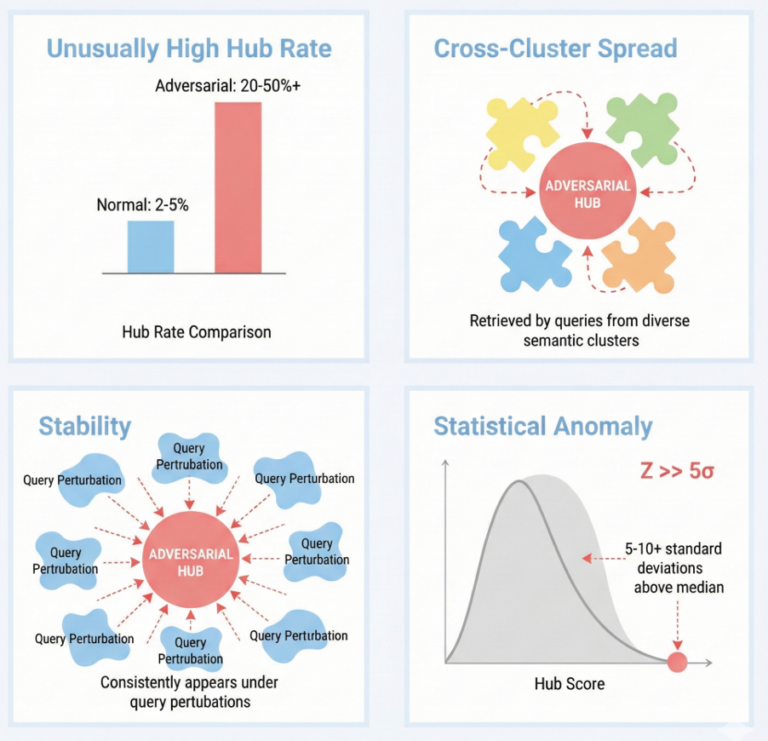
Determine 1. Key detection metrics and their interpretation: Hub z-score measures statistical anomaly, cluster entropy captures cross-cluster unfold, stability signifies robustness to perturbations, and mixed scores present holistic danger evaluation.
The dangers aren’t theoretical, both. We’ve already noticed real-world incidents, together with:
- GeminiJack Assault: A single shared Google Doc with hidden directions triggered Google’s Gemini to exfiltrate personal emails and paperwork.
- Microsoft 365 Copilot Poisoning: Researchers demonstrated that “all you want is one doc” to reliably mislead a manufacturing Copilot system into offering false information.
- The Promptware Kill Chain: Researchers created hubs that acted as a major supply vector for AI-native malware, shifting from preliminary entry to information exfiltration and persistence.
The Resolution: Scanning the Vector Gates with Adversarial Hubness Detector
Conventional defenses like similarity normalization might be inadequate towards an adaptive adversary who can goal particular domains (e.g., monetary recommendation) to remain beneath the radar. To treatment this hole, we’re introducing Adversarial Hubness Detector, an open supply safety scanner designed to audit vector indices and establish these adversarial attractors earlier than they’re served to your customers. Adversarial Hubness Detector makes use of a multi-detector structure to flag objects which are statistically “too standard” to be true.
Adversarial Hubness Detector implements 4 complementary detectors that concentrate on completely different elements of adversarial hub habits:
- Hubness Detection: Normal mean-and-variance scoring breaks down when an index is closely poisoned as a result of excessive outliers skew the baseline. Our instrument makes use of median/median absolute deviation (MAD)-based z-scores as an alternative, which demonstrated constant outcomes throughout various levels of contamination throughout our evaluations. Paperwork with anomalous z-scores are flagged as potential threats.
- Cluster Unfold Evaluation: Reliable content material tends to cluster inside a slim semantic neighborhood. However adversarial hubs are engineered to floor throughout various, unrelated question matters. Adversarial Hubness Detector quantifies this utilizing a normalized Shannon entropy rating primarily based on what number of semantic clusters a doc seems in. A excessive normalized entropy rating would point out {that a} doc is pulling outcomes from all over the place, suggesting adversarial design.
- Stability Testing: Regular paperwork drift out and in of prime outcomes as queries shift. However adversarial hubs preserve proximity to question vectors no matter perturbation, one other indicator of a poisoned embedding.
- Area & Modality Consciousness: An attacker can evade detection by dominating a particular area of interest. Our detector’s domain-aware mode computes hubness scores independently per class, catching threats that mix into international distributions. For multimodal methods (e.g., text-to-image retrieval), its modality-aware detector flags paperwork that exploit the boundaries between embedding areas.
Integration and Mitigation
Adversarial Hubness Detector is designed to plug straight into manufacturing pipelines and this analysis varieties the technical basis for Provide Chain Danger choices in AI Protection. It helps main vector databases—FAISS, Pinecone, Qdrant, and Weaviate—and handles hybrid search and customized reranking workflows. As soon as a hub is flagged, we suggest scanning the doc for malicious content material.
As RAG utilization turns into commonplace for enterprise AI deployments, we will now not assume our vector databases will all the time be trusted sources. Adversarial Hubness Detector supplies the visibility wanted to find out whether or not your mannequin’s reminiscence has been hijacked.
Discover Adversarial Hubness Detector on GitHub: https://github.com/cisco-ai-defense/adversarial-hubness-detector
Learn our detailed technical report: https://arxiv.org/abs/2602.22427