

{kind=link}
The material determination that defines margins
An enterprise CFO opinions AI spend: coaching payments are spiking at a hyperscaler the place they have already got contracts in place, even when their information doesn’t stay solely there; inference efficiency is lagging; and a neocloud pilot is on the desk. Solely a yr or two in the past, sensible selections had been largely restricted to hyperscalers; the current explosion of AI has made neoclouds an actual choice for a lot of organizations as they mature and study they’ve alternate options after they hit limits on efficiency, value, flexibility, service, or GPU availability. The query isn’t whether or not to make use of a neocloud; it’s whether or not that neocloud can seize the total AI lifecycle—coaching and manufacturing inference—or only a one-time challenge.
Throughout the market, suppliers with comparable GPU footprints are seeing very totally different outcomes. Some watch prospects prepare fashions on their infrastructure, then transfer manufacturing workloads elsewhere. For each greenback of coaching income retained, a number of {dollars} of higher-margin inference income stroll out the door. Others are seeing inference income rising sooner than coaching, gross margins increasing from the mid-teens towards the high-30s, and valuations that replicate sturdy platform economics fairly than commodity pricing. With 1000’s of AI tasks now underway globally, it’s not shocking that totally different suppliers see barely totally different patterns, however clear tendencies are rising in how architectures and enterprise fashions correlate.
The distinction isn’t higher GPUs or short-term reductions. Suppliers pulling forward have made one particular architectural wager: unified AI materials able to working coaching and inference concurrently at excessive efficiency, backed by a unified management airplane. It is a structural determination that compounds through the years. When you select between twin materials and a unified material, you could have successfully chosen your margin profile.
The economics are stark. A dual-fabric supplier working separate coaching and inference infrastructures carries elevated capital and operational prices, constrained flexibility, and margins that are inclined to settle within the mid-teens. A unified-fabric competitor with an identical GPU depend handles each workloads on a single material—capturing inference SLAs alongside coaching jobs, shifting the enterprise combine towards higher-margin recurring income, and driving larger valuation multiples within the course of. In real looking situations, the gross revenue hole between these two paths can attain lots of of hundreds of thousands of {dollars} at scale. That hole determines who has the money movement to maintain investing—and who will get left behind in a consolidating market. That makes it important for neoclouds to ask not solely how their material is constructed, but additionally what share of their enterprise mannequin is tuned towards higher-margin, recurring inference versus one-off coaching tasks.
Platform or GPU dealer?
By means of 2024 and 2025, the dominant neocloud pitch was simple: GPU entry at costs beneath hyperscalers. That differentiation nonetheless issues for a lot of purchasers, however new determination standards are rising: Does the neocloud personal and function the GPUs? Do prospects get direct entry to level-3 consultants in AI networking and GPU optimization? Can the supplier troubleshoot throughout the total stack and supply devoted or shared GPU environments with advisory and benchmarking help earlier than a dedication? Whereas these could sound like minor factors, they change into vital when a coaching or inference cluster stops working, and the query is: who can repair it, how briskly, and when?
For some segments, the pure worth hole is narrowing as the most important neoclouds and hyperscalers converge on comparable capability, whereas many rising neoclouds nonetheless supply considerably decrease efficient TCO as soon as service, help, storage, and microservices are included. In some areas and for some massive consumers, hyperscalers seem to have caught up on GPU provide, but many organizations with modest and even vital AI footprints nonetheless expertise shortages within the kind, timing, and site of capability they want. Pricing continues to compress. Competing on “cheaper GPU rental” alone is a race to the underside.
The suppliers that survive by means of 2030 are more likely to look much less like GPU resellers and extra like built-in AI platforms—managing coaching, inference, fine-tuning, and iteration so prospects can run AI as a enterprise functionality, not a one-off challenge. Platform suppliers command pricing energy and stickiness: when a buyer’s suggestion engine, fraud detection, and personalization fashions all run on built-in infrastructure, switching prices change into prohibitive. They don’t re-evaluate suppliers for every new challenge. The widespread sample is evident: the winners behave like platforms and supply differentiated companies, not purely as GPU resellers with no worth add.
The shopper lifecycle makes this concrete. A retailer trains a suggestion mannequin on a couple of hundred GPUs and now must serve 1000’s of inference requests per second with strict latency SLAs for his or her e-commerce website. A dual-fabric neocloud can’t assure these manufacturing SLAs alongside different tenants—the shopper is steered to a hyperscaler, and the neocloud is left with a one-off coaching win and hundreds of thousands in misplaced lifecycle income. A unified material neocloud deploys the identical mannequin into manufacturing on the identical infrastructure, with no second vendor, no information migration, no egress charges, and no new tooling. Twelve months later, fine-tuning and new use circumstances land on the identical platform. Inside two years, the shopper has standardized on the platform.
Why coaching materials fail at inference
Coaching and inference symbolize essentially opposed visitors patterns flowing by means of the identical bodily community. Giant-scale coaching requires synchronized gradient updates throughout 1000’s of GPUs—bulk, predictable, megabytes per synchronization step. The workload tolerates transient delays; a congestion spike that extends coaching time barely is appropriate. Conventional coaching materials optimize for precisely this: adequate buffering to soak up bursts, excessive bandwidth, and congestion-aware routing.
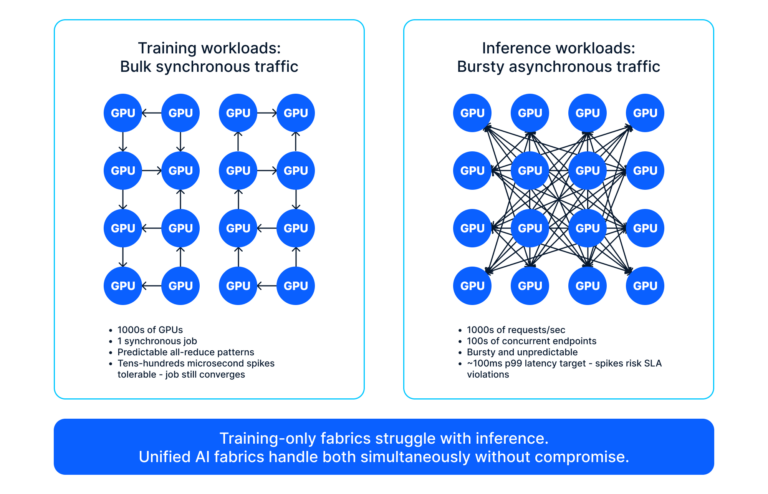
As proven in Determine 1, inference visitors is the other. Requests arrive asynchronously from many shoppers at unpredictable intervals, each small—kilobytes fairly than megabytes—and each latency-critical. When a manufacturing software expects 80ms and receives 200ms, SLA penalties loom. The buffering tuned for bulk coaching visitors can add latency to small inference requests queued behind gradient bursts. Operations groups typically reply by segregating workloads onto separate racks and materials, creating two infrastructures with duplicate capital and operational overhead.
Unified material structure
Unified materials carry workload consciousness into the community itself. When gradient visitors flows, the material acknowledges it as bulk synchronous communication, routes it to paths with acceptable buffering, and lets it queue briefly. When inference requests arrive concurrently, the material identifies them as latency-critical and steers them onto the lowest-latency paths—defending SLAs with out ravenous coaching.
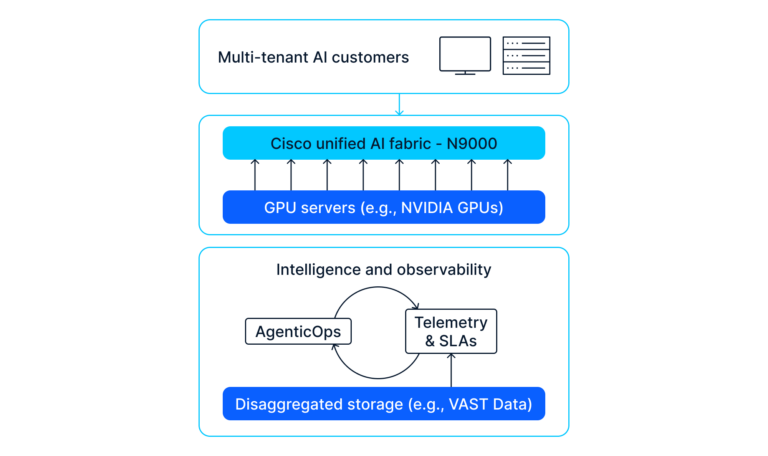
Cisco N9000 Sequence Switches present silicon-level help for this mannequin: sub-5-microsecond material latencies for quick collective operations, RoCEv2-based lossless Ethernet with ECN and PFC for large-scale coaching, and deep shared buffers to soak up gradient bursts. On the similar time, workload-aware congestion administration and stay in-band telemetry keep latency ensures for inference flows beneath heavy load.
On the rack degree, Cisco N9100 switches constructed on NVIDIA Spectrum-X Ethernet Silicon deal with GPU-to-GPU collectives whereas imposing per-rack isolation for multi-tenant inference. Disaggregated storage platforms comparable to VAST Knowledge serve each workloads on the identical community—coaching checkpoints, mannequin repositories, and inference request information—all with acceptable prioritization.
Actual-time intelligence beneath load
The management airplane determines whether or not unified material intelligence is usable at scale. Cisco Nexus One and Cisco Nexus Dashboard present a unified administration layer—centralizing telemetry, automation, and coverage enforcement—so multi-tenant AI clusters function as a single platform fairly than a patchwork of domains.
Take into account the strain check: a big pre-training job working throughout 1000’s of H100-class GPUs, with inference endpoints serving manufacturing fashions for dozens of enterprise prospects concurrently. A buyer’s software goes viral; inference request charges bounce two orders of magnitude in beneath a minute.
On a training-optimized material, the sequence is acquainted: inference visitors floods into gradient bursts; P99 latency blows previous SLA thresholds, timeouts cascade, and incident channels mild up. Even after the coaching job is throttled, the injury to SLA metrics and buyer belief is completed.
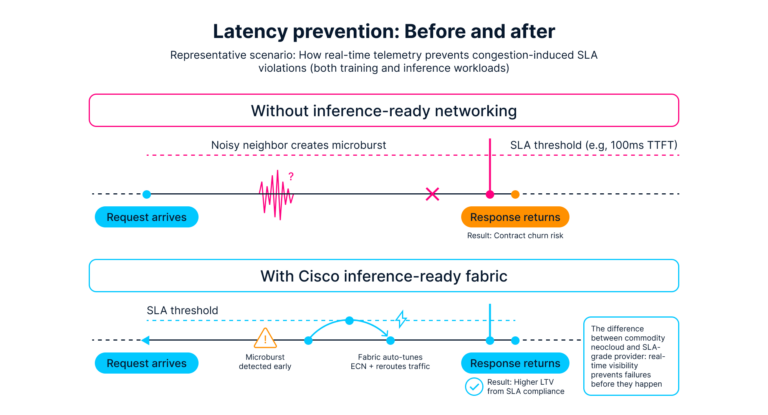
On a unified material with Cisco Nexus One because the management airplane, the response is automated. In-band telemetry surfaces the visitors shift; the material auto-tunes insurance policies: inference visitors receives precedence lanes, coaching visitors shifts to alternate paths with deeper buffering, and express congestion notifications information coaching senders to briefly scale back price. The coaching job’s all-reduce time will increase solely marginally—inside convergence tolerance—whereas inference stays inside its P99 SLA. No guide intervention. No SLA violation. The operations crew watches the whole lot on a single dashboard: coaching convergence metrics, inference latency distributions per tenant, and the material’s personal actions.
The price of delay
A supplier working separate materials may inform itself that unified material can anticipate the following budgeting cycle. In the meantime, a competitor deploys unified material this yr. Inside a couple of quarters, that competitor begins capturing prospects whom the primary supplier skilled however couldn’t serve in manufacturing. Their margins enhance. Their subsequent funding spherical costs in platform economics, not commodity pricing.
By the point the primary supplier decides to behave, tens or lots of of hundreds of thousands could already be tied up in twin materials. Retrofitting unified material turns into a multi-year migration as a substitute of a clear construct—and through that window, probably the most helpful prospects are signing multi-year platform agreements with another person.
The market is consolidating. The window to guide fairly than comply with is slim. For neocloud CEOs, CTOs, and infrastructure leads, the material determination made this yr will decide whether or not your group turns into a differentiated AI platform or stays a GPU dealer in a market that not rewards commodity capability.
Unified networks: The strategic selection
Cisco works with neoclouds and progressive suppliers worldwide to construct safe, environment friendly, and scalable AI platforms that ship outcomes throughout your entire mannequin lifecycle. Detailed AI material white papers, design guides, and associate reference architectures—with full metrics, check information, and topologies—can be found for readers who need to go deeper.
Further assets: